
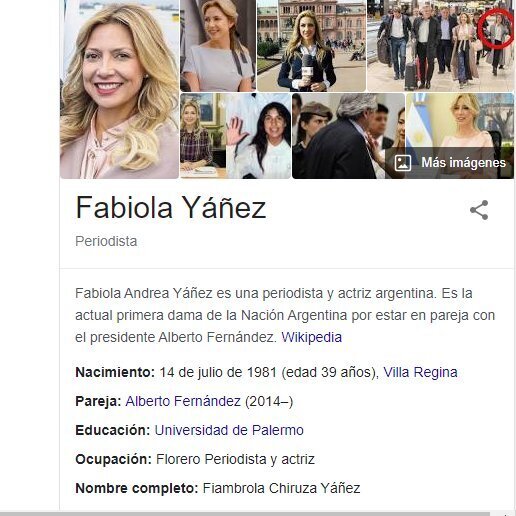
Este jueves, el panel de conocimiento de Google mostró un agravio contra la primera dama, Fabiola Yáñez. Al igual que pasó con la vicepresidenta Cristina Fernández de Kirchner, quien aparecía calificada como “ladrona de la Nación”, el buscador exhibe un nombre completo falso de la primera dama y señala que su profesión es “Florero, periodista y actriz”.
Si alguien buscaba este jueves en Google a Yáñez, la página mostraraba un fragmento de su biografía de Wikipedia y, un poco más abajo, algunos datos de la primera dama, entre ellos un falso y agraviante “nombre completo”: “Fiambrola Chiruza Yáñez”.
Este año, Cristina Fernández de Kirchner hizo una presentación judicial contra la empresa Google después de que el 17 de mayo de 2020 a las 00:20hs el diario Clarín publicó, en una una nota digital, que el buscador de Google había colocado una infamante leyenda en el lugar donde debería figurar el cargo que ocupa hoy.
Como respuesta a la denuncia de la expresidenta, Google emitió un breve comunicado de prensa en el que explicaba que el panel de conocimiento “se genera de forma automática, tomando información de diferentes fuentes de la web".
La justicia hizo lugar a la denuncia de CFK y le permitió acceder a todos los datos asociados a ella “a partir del 17/05/2020 hasta el día en que se realice la presente pericia, que surjan del contenido del panel de conocimiento del buscador ‘Google’”.
La empresa presentó una apelación que fue rechazada y, después, intentó llevar el caso a la Corte Suprema de Justicia de la Nación que declaró el recurso como “inadmisible”.
Los lineamientos de Google
Entre sus alcances, Google explica cómo funcionan los paneles de conocimiento y detalla que aquel gráfico "mapea automáticamente los atributos y las relaciones de estas entidades del mundo real a partir de información recopilada de la web, bases de datos estructuradas, datos bajo licencia y otras fuentes".
"La información del Gráfico de conocimiento debe estar basada en hechos y se presenta como tal. Sin embargo, aunque nuestro objetivo es ser lo más precisos posible, nuestros sistemas no son perfectos, ni tampoco las fuentes de datos disponibles", recalcan.
Para identificar información inexacta, siguen un protocolo específico. "Recopilamos los comentarios de los usuarios, y si descubrimos que algo es incorrecto y que nuestros sistemas no se han autocorregido, podemos verificar y actualizar la información manualmente".
Por otro lado, indican que "han desarrollado herramientas y procesos para ofrecer estas correcciones a fuentes como Wikipedia, con el objetivo de mejorar el ecosistema de información de manera más amplia".
En caso de que haya una imagen o una vista previa de los resultados de la Búsqueda de imágenes de Google que se muestre en un Panel de conocimiento y no represente con precisión a la persona, el lugar u objeto, también se corrige el error.

