![]()
![]()
![]() Domingo, 20 de febrero de 2011
| Hoy
Domingo, 20 de febrero de 2011
| Hoy
Domingo, 20 de febrero de 2011
CULTURA › NGRAM VIEWER ANALIZA LAS PALABRAS QUE SE USAN EN LOS LIBROS DE TODO EL MUNDO
Un chiche para quienes aman clasificar
Con la nueva herramienta de Google, ahora es posible seguir a vuelo de pájaro el proceso de nacimiento, desarrollo, reproducción y muerte de las expresiones lingüísticas, un campo que los especialistas han empezado a llamar Culturomics.




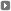 Por Facundo García
Por Facundo García
¿Quién aparece más en los libros que se escriben en español, Dios o el diablo? ¿Elisa Carrió o Roberto Gómez Bolaños? Esas y otras incógnitas pueden averiguarse con Ngram Viewer, uno de los últimos chiches que estrenó Google. En medio de su fiebre por clasificarlo todo, el gigante web se propuso generar una herramienta que analizara la cantidad de veces que se utilizaron diferentes palabras o frases en la maraña de volúmenes publicados desde 1880. Así, ahora es posible seguir a vuelo de pájaro –y no sin salvedades, claro– el proceso de nacimiento, desarrollo, reproducción y muerte de las expresiones lingüísticas, un campo que los especialistas han empezado a llamar Culturomics (www.cultu romics.org).
Tras un par de minutos jugueteando en el sitio, la mente de cualquier usuario más o menos informado verá germinar decenas de hipótesis. Las más inmediatas surgen al evaluar la “vida” de vocablos cotidianos: comparar la historia de “boludo” con la de “pelotudo” y la de “atorrante”, sin ir más lejos, revela un franco crecimiento del primer término a partir de mediados de los ’90. Muy distinto fue el devenir de “atorrante”, que reinó en los ’60 y mantiene una vigencia relativa. “Pelotudo”, por su parte, exhibe una curva más estable. ¿Estarán aumentando los boludos y disminuyendo los atorrantes? ¿O acaso cayeron los rótulos que prohibían a las “malas palabras”, y eso facilita su ingreso al tejido textual?
Habrá que seguir indagando. De todos modos, un segundo cuarto de hora con el Ngram Viewer deja la impresión de que el lenguaje es un objeto sumamente movedizo. Es más: una de las sorpresas que se llevaron los expertos fue comprobar que alrededor del 52 por ciento de las palabras que se utilizan en los libros en inglés no figura en los diccionarios. Se trata, según su propia denominación, de “materia oscura lexicográfica”, el magma que da dinamismo a un idioma. En cuanto al castellano, se anticipa que ese porcentaje podría ser similar o mayor.
El asunto tiene costados menos abstractos. Incluso se puede investigar la expansión y decadencia de innovaciones tecnológicas anotando la asiduidad con que se las menciona. O sea: no es azaroso que “email”, “fax” y “teléfono” hayan circulado de forma disímil en diferentes épocas. En ese sentido, lo que salta a la vista es que el período para que un invento alcance máxima difusión en el universo de lo escrito resulta cada vez más corto. El ritmo de las novedades se está acelerando. Y hablando de ritmo: operaciones parecidas son aplicables a los géneros musicales, las figuras literarias o los fenómenos relacionados con tensiones sociales. “Mujer” y “hombre”, por citar un ejemplo, vienen acortando distancias; y “homosexual” ascendió marcadamente en vísperas del tercer milenio.
Otra punta interesante es la de las huellas que deja la censura en el paisaje de lo escrito. La prohibición que impuso el nazismo sobre el pintor judío Marc Chagall se vuelve evidente al contrastar la presencia de ese nombre en la literatura en inglés y en alemán durante el lapso 1910-1945. Ni hablar de lo que pasa con Trotsky en las ediciones rusas. Fuera de esos extremos, la memoria colectiva también hace sus apuestas. Según la base de datos, “dictadura argentina” tuvo una fuerte influencia en los libros de los ’80, y a principios de los ’90 decayó sensiblemente, para posicionarse luego en su actual techo histórico. Y Dios no está necesariamente muerto: la gente simplemente se olvidó de él. Su frecuencia de aparición en las páginas ha descendido a la mitad si se la coteja con la de los libros editados en 1860. Menos alarmante es la situación de “diablo”, que cayó hacia 1980 pero hoy tiene bríos como para seguir avanzando, al igual que Elvis y Gauchito Gil.
El nombre Ngram Viewer proviene del término “n-grama”, que se usa en ciertos círculos académicos para designar a los fragmentos de una secuencia más grande hecha de sílabas, letras, etcétera. “Viewer”, por supuesto, significa “visor”. Lo que Google hace, entonces, es contar la cantidad de oportunidades en que se “producen” n-gramas de hasta cinco términos, ilustrando las caídas y alzas de ese número en un cuadro cronológico.
Para confeccionar los gráficos se analizan nada menos que 5,2 millones de libros en chino, inglés, francés, alemán, ruso y español. De ser cierto, eso equivaldría a 500 mil millones de palabras, aproximadamente el cuatro por ciento de lo que ha publicado la humanidad. Se objetará –y con razón– que aunque sean números siderales, no pueden interpretarse como una muestra representativa de toda la cultura. No obstante, el Ngram Viewer se vale del corpus más enorme que existe. Por otro lado, la selección que eligió Google no incluye la totalidad de las 12 millones de obras que la compañía ha escaneado hasta la fecha. Llegado este punto, el vértigo es inevitable.

El gráfico permite ver la evolución por décadas del n-grama “dictadura argentina”.
Compartir:



-
TEATRO> CARLOS GOROSTIZA Y AGUSTIN ALEZZO, JUNTOS EN VUELO A CAPISTRANO
Los símbolos eternos de la libertad
Figuras indiscutibles del teatro nacional, por primera vez unen sus talentos para una obra. El...
Por Carolina Prieto -
TEATRO > OPINION
Los saberes de una dupla
Por Juan Carlos Gené -
CULTURA > NGRAM VIEWER ANALIZA LAS PALABRAS QUE SE USAN EN LOS LIBROS DE TODO EL MUNDO
Un chiche para quienes aman clasificar
Por Facundo García -
LITERATURA > HERNAN VANOLI HABLA DE SU NOVELA PINAMAR, PUBLICADA POR INTERZONA
Por los claroscuros del peronismo
Por Silvina Friera -
MUSICA > OPINION
La libertad de Radiohead
Por Eduardo Fabregat -
CINE > NADER Y SIMIN, UNA SEPARACION GANO LA COMPETENCIA OFICIAL EN BERLIN
El Oso de Oro fue para el favorito
Por Luciano Monteagudo -
VISTO & OIDO
VISTO & OIDO
![]()
© 2000-2022 www.pagina12.com.ar | República Argentina | Política de privacidad | Todos los Derechos Reservados
Sitio desarrollado con software libre GNU/Linux.